
Performance of C++ code exported by RNBO

I tried exporting the biquad filter sub-patch in RNBO Guitar Pedals to C++ code.
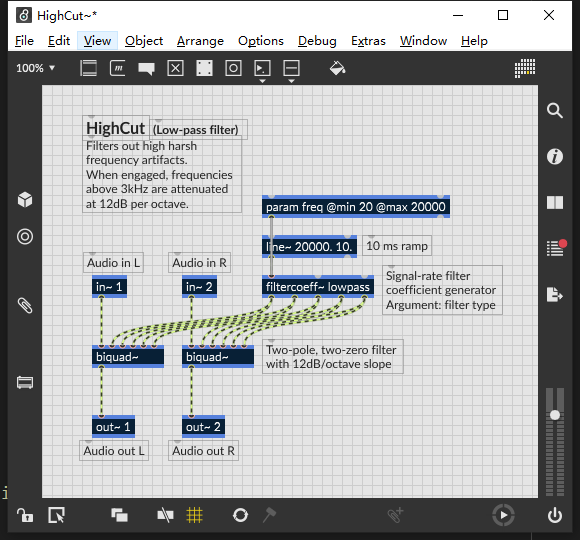
Its performance is much lower than other filter implementations. The reasons include but are not limited to the repeated calculation of filter coefficients. Does Cycling '74 plan to optimize the exported C++ code? performance.

Hi TG Alpha,
Thanks for the report. The RNBO filtercoeff~ object is not currently testing input parameters and only calculating the coefficients when they change, or only generating new filter coefficients by default once per signal vector like the MSP version does. We can implement the first (test incoming values and only generate unique ones), but the second is easily accomplished in your patch by using the resamp option--e.g. filtercoeff~ lowpass @resamp 16, which will only calculate the filter coefficients once every 16 samples and provide ~16x performance increase for your use case.
-Joshua
Hi Joshua Kit Clayton,
Thanks for the suggestion. I have tried manually modifying the exported code so that the filter coefficients are calculated only once during initialization. The result is that its performance is still significantly lower than other filters.

I think the code exported by biquad~ patch also has room for optimization
Hi TG Alpha,
If you can provide a link, I'd be happy to look at an example project in greater detail (feel free to send into support referencing this thread if you'd prefer).
There could be any number of things at play, but I'd be surprised if the biquad implementation were the culprit in this case. Also make sure that you are building the project with release settings on (e.g. -O2 or higher).
Thanks,
Joshua
Hi Joshua Kit Clayton,
Sorry for the delay. I uploaded the wwise plugin project to github. Since I am using RNBO in demo mode, I cannot save the patch, so there are only exported c++ codes in the repo. The patch content is the same as the screenshot. Hope this provides enough information. 🙏
https://github.com/tgalpha/wwise-max-lowpass
Thanks
Hi TG Alpha,
Thank you for taking the time to provide this example and following up so that we can solve any performance issues.
It will be some time before I get setup to be able to test this clearly within the wwise toolchain. In the meantime, perhaps there are a few tests you could run to help diagnose the issue sooner.
Reviewing the code, it is apparent that the coefficients will be calculated once every audio vector (filtercoeff's resampling rate is equal to the audio buffer vector size by default). The coefficient calculation should by far be the most expensive thing that this patcher is doing, but there may be some things about the wwise plugin model or other factors on our end that I am not taking into account.
Could you possibly verify how large the signal vector size you are processing via wwise (i.e. size of in/out sample buffers processed within "Execute")?
Another way to rule out the coefficient calculation would be to use an extremely high resampling rate for filtercoeff--e.g. 512 like the attacher below. If the following patcher has significantly improve performance within your workflow, we can assume that it is the filter coefficient calculation that is at fault here, and if it does not, the problem may lie elsewhere (there could also be some problems at play within the initialization of variables for the filter coefficient resampling interval, FWIW, which would be a compound problem here but still related to the coefficient calculation...that could be overridden by explicitly replacing the use of filtercoeff_01_activeResamp with 512 in the exported code for example).
Here is a patcher to test with:
Thanks again,
Joshua
Hi Joshua Kit Clayton,
Thanks for your reply.
Wwise Authoring Buffer size can be set in `Audio-Authoring Audio Preference`. The default value should be 512. That is the value I passed to `prepareToProcess`.
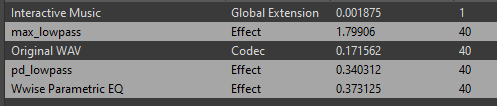
I tested it with the patcher you provided, and the performance is even worse. It may be because the original buffersize is 512, and resampling brings additional consumption.
In addition, I also uploaded the wwise project for testing.
After the plugin has been deployed to wwise, here is my test method:
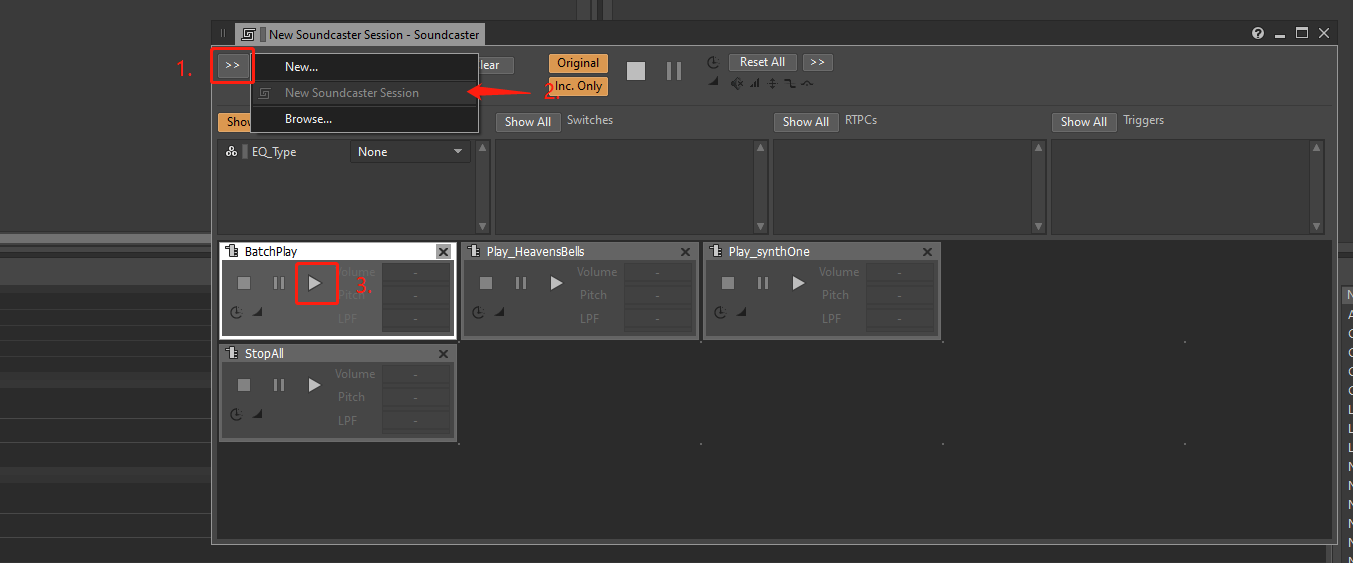
1. Press `F6` to switch to Profiler layout
2. Press `Alt + C` to start capture

3. Press `Shift + S` to open Soundcaster, switch to `New Soundcaster Session`, click `BatchPlay`, this will create 40 voice instances at the same time (be careful with the volume) to observe the performance difference more clearly.
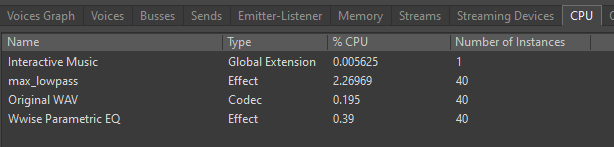
4. In the `CPU` tab of the `Advanced Profiler` window, you can see the CPU statistics
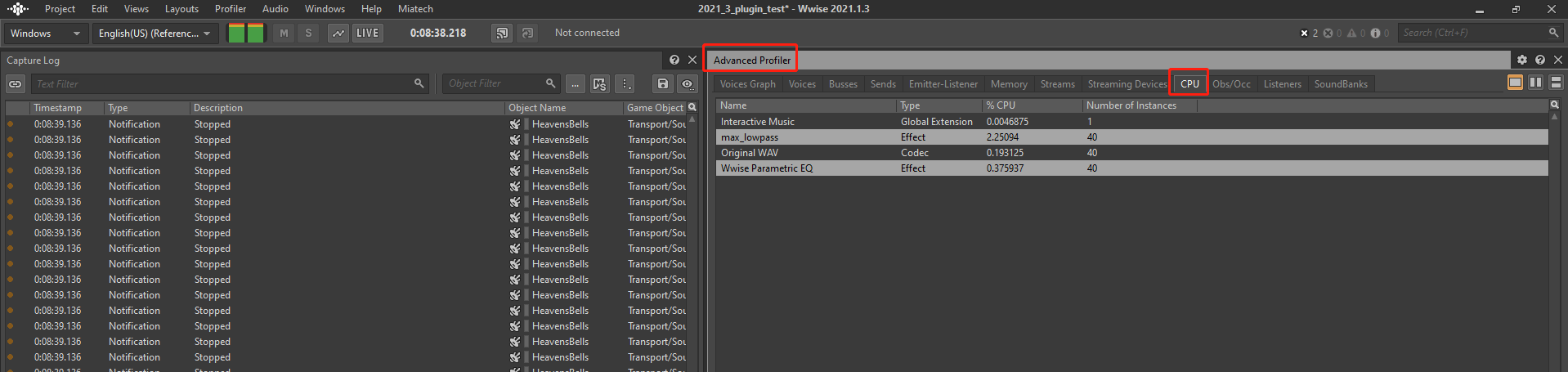
I hope this can be convenient for you.
Thanks
Hi TG Alpha,
Thank you for following up and confirming this behavior. So it definitely points to additional overhead unrelated to the coefficient calculation. There's a couple things that come to mind to try until we are able to make dedicated time to test with this example in wwise.
Try defining RNBO_USE_FLOAT32 within your compiler definitions. This will make use of 32bit audio buffers and 32bit precision calculations. Otherwise, the way you're passing in 32bit floating point buffers to the RNBO code, it will allocate and free 64bit floating point buffers with each call to process(). Alternatively, you could allocate and manage your own 64 bit floating point buffers, passing into the process() call.
There are additional event/midi/parameter queues which are serviced within each process call, which may have some noticeable overhead that other wwise plugins do not have. You could try doing a little bit of surgery in Engine::process() and EngineCore::process() to do as little as possible except call _patcher->process() to see if that clears up more overhead.
We'll get around to looking at this in more detail in the not too distant future, but I wanted to at least give some suggestions of experiments you could try while you wait for us to get around to it, if you wanted to. If you do take the time to explore further, please let us know any findings and ways we could improve RNBO.
Best,
Joshua
Hi Joshua Kit Clayton,
Thanks for your reply, about your two proposals:
1. I have defined RNBO_USE_FLOAT32 in the premake script `PremakePlugin.lua`. In this way, every premake project will add this flag.
2. I tried to bypass the processing of event/midi/parameter in EngineCore, but the performance did not change much. Related changes can be checked out from git repo.
If there are other discoveries I will continue to reply in this thread. Hope your research goes well.
Thanks