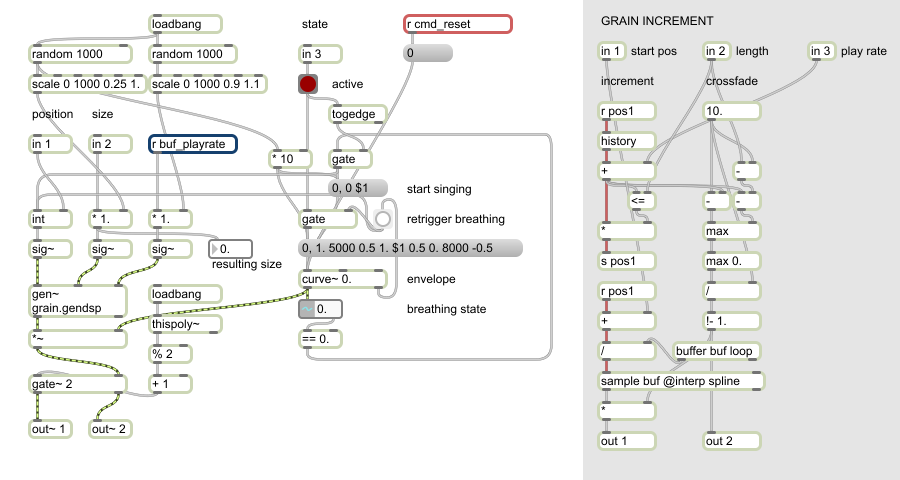
The project is implemented in pure Max 6 and Gen.
Year
March 2014
Location
Electronic Studio, Technische Universität Berlin
Links
http://blog.sebastian-arnold.net/2014/10/she-was-a-visitor/
Author