
[coll] and editing entire columns at once

I am using a coll object to create "segments" of audio files so they can be played in various sequences. sometimes, I need to adjust where a segment starts to match a transient. The patch I have attached chooses the segment to edit... and makes adjustments to the coll data with respects to the current "start" time and preceding "end" time for coherence of the ictus of the sound segment.
I am wondering if it's possible to adjust ALL values in a column below a specific address at once... in this example i would like to adjust all values so the adjustment happening in this patch can plus or minus each of those values relative. Thanks.
Here is an example of a cue sheet for reference. Maybe load this into coll to try what I have so far. the forum wouldn''t let me attach the actual coll file:
the list is (address) (start ms) (end ms) (measure) (beat) (placeholder) which is used to both arrange the clips and address a [play~] object to sequence the segments of audio...
1, 0 521.74 1 1;
2, 521.74 1043.48 1 2 0;
3, 1043.48 1565.22 1 3 0;
4, 1565.22 2086.96 1 4 0;
5, 2086.96 2608.7 2 1 0;
6, 2608.7 3130.44 2 2 0;
7, 3130.44 3652.18 2 3 0;
8, 3652.18 4173.92 2 4 0;
9, 4173.92 4695.66 3 1 0;
10, 4695.66 5217.4 3 2 0;
11, 5217.4 5739.14 3 3 0;
12, 5739.14 6260.88 3 4 0;
13, 6260.88 6782.62 4 1 0;
14, 6782.62 7304.36 4 2 0;
15, 7304.36 7826.1 4 3 0;
16, 7826.1 8347.84 4 4 0;
17, 8347.84 8869.58 5 1 0;
18, 8869.58 9391.32 5 2 0;
19, 9391.32 9913.06 5 3 0;
20, 9913.06 10434.8 5 4 0;
21, 10434.8 10956.54 6 1 0;
22, 10956.54 11478.28 6 2 0;
23, 11478.28 12000.02 6 3 0;
24, 12000.02 12521.76 6 4 0;
25, 12521.76 13043.5 7 1 0;
26, 13043.5 13565.24 7 2 0;
27, 13565.24 14086.98 7 3 0;
28, 14086.98 14608.72 7 4 0;
29, 14608.72 15130.46 8 1 0;
30, 15130.46 15652.2 8 2 0;
31, 15652.2 16173.94 8 3 0;
32, 16173.94 16695.68 8 4 0;
33, 16695.68 17217.42 9 1 0;
34, 17217.42 17739.16 9 2 0;
35, 17739.16 18260.9 9 3 0;
36, 18260.9 18782.64 9 4 0;
37, 18782.64 19304.38 10 1 0;
38, 19304.38 19826.12 10 2 0;
39, 19826.12 20347.86 10 3 0;
40, 20347.86 20869.6 10 4 0;
41, 20869.6 21391.34 11 1 0;
42, 21391.34 21913.08 11 2 0;
43, 21913.08 22434.82 11 3 0;
44, 22434.82 22956.56 11 4 0;
45, 22956.56 23478.3 12 1 0;
46, 23478.3 24000.04 12 2 0;
47, 24000.04 24521.78 12 3 0;
48, 24521.78 25043.52 12 4 0;
49, 25043.52 25565.26 13 1 0;
50, 25565.26 26087. 13 2 0;
51, 26087. 26608.74 13 3 0;
52, 26608.74 27130.48 13 4 0;
53, 27130.48 27652.22 14 1 0;
54, 27652.22 28173.96 14 2 0;
55, 28173.96 28695.7 14 3 0;
56, 28695.7 29217.44 14 4 0;
57, 29217.44 29739.18 15 1 0;
58, 29739.18 30260.92 15 2 0;
59, 30260.92 30782.66 15 3 0;
60, 30782.66 31304.4 15 4 0;
61, 31304.4 31826.14 16 1 0;
62, 31826.14 32347.88 16 2 0;
63, 32347.88 32869.62 16 3 0;
64, 32869.62 33391.36 16 4 0;
65, 33391.36 33913.1 17 1 0;
66, 33913.1 34434.84 17 2 0;
67, 34434.84 34956.58 17 3 0;
68, 34956.58 35478.32 17 4 0;
69, 35478.32 36000.06 18 1 0;
70, 36000.06 36521.8 18 2 0;
71, 36521.8 37043.54 18 3 0;
72, 37043.54 37565.28 18 4 0;
73, 37565.28 38087.02 19 1 0;
74, 38087.02 38608.76 19 2 0;
75, 38608.76 39130.5 19 3 0;
76, 39130.5 39652.24 19 4 0;
77, 39652.24 40173.98 20 1 0;
78, 40173.98 40695.72 20 2 0;
79, 40695.72 41217.46 20 3 0;
80, 41217.46 41739.2 20 4 0;
81, 41739.2 42260.94 21 1 0;
82, 42260.94 42782.68 21 2 0;
83, 42782.68 43304.42 21 3 0;
84, 43304.42 43826.16 21 4 0;
85, 43826.16 44347.9 22 1 0;
86, 44347.9 44869.64 22 2 0;
87, 44869.64 45391.38 22 3 0;
88, 45391.38 45913.12 22 4 0;
89, 45913.12 46434.86 23 1 0;
90, 46434.86 46956.6 23 2 0;
91, 46956.6 47478.34 23 3 0;
92, 47478.34 48000.08 23 4 0;
93, 48000.08 48521.82 24 1 0;
94, 48521.82 49043.56 24 2 0;
95, 49043.56 49565.3 24 3 0;
96, 49565.3 50087.04 24 4 0;
97, 50087.04 50608.78 25 1 0;
98, 50608.78 51130.52 25 2 0;
99, 51130.52 51652.26 25 3 0;
100, 51652.26 52174. 25 4 0;
101, 52174. 52695.74 26 1 0;
102, 52695.74 53217.48 26 2 0;
103, 53217.48 53739.22 26 3 0;
104, 53739.22 54260.96 26 4 0;
105, 54260.96 54782.7 27 1 0;
106, 54782.7 55304.44 27 2 0;
107, 55304.44 55826.18 27 3 0;
108, 55826.18 56347.92 27 4 0;
109, 56347.92 56869.66 28 1 0;
110, 56869.66 57391.4 28 2 0;
111, 57391.4 57913.14 28 3 0;
112, 57913.14 58434.88 28 4 0;
113, 58434.88 58956.62 29 1 0;
114, 58956.62 59478.36 29 2 0;
115, 59478.36 60000.1 29 3 0;
116, 60000.1 60521.84 29 4 0;
117, 60521.84 61043.58 30 1 0;
118, 61043.58 61565.32 30 2 0;
119, 61565.32 62087.06 30 3 0;
120, 62087.06 62608.8 30 4 0;
121, 62608.8 63130.54 31 1 0;
122, 63130.54 63652.28 31 2 0;
123, 63652.28 64174.02 31 3 0;
124, 64174.02 64695.76 31 4 0;
125, 64695.76 65217.5 32 1 0;
126, 65217.5 65739.24 32 2 0;
127, 65739.24 66260.98 32 3 0;
128, 66782.72 67304.46 33 1 0;

I don't understand the problem.
If you want to shift all times 10 ms
then uzi as many lines as you want and nsub them.

one could also querry coll length to adjust uzi etc etc...
Wow! This is amazing thank you! I'm a bit of a smooth brain, and I wish I understood how this works and more about using vexpr. Obviously the uzi argument is how many subsequent indicies are modified... this is actually more useful than what I thought I wanted because not only can I modify all remaining entries, I realize now I can also set a "range."
Thanks again, this is really great.
nsub message replaces value at set coll index, and data index.
example : nsub 22 3 100
this coll line :
22, 1 2 3 4 5 6;
becomes
22, 1 2 100 4 5 6;
that because data indexes start from 1 up.
to change 2 data values, separate messages with comma to iter them
nsub 22 3 100, nsub 22 4 99
makes
22, 1 2 100 99 5 6;
........
it is now only matter to decide what to replace with what value(s)...
vexpr in scalar mode 1 performs calculation on lists.
in this case we collect 2 data values from coll
and add a value to it.
actually easy.
for your data list you need to extract only that 2 first values, either using zl.slice 2
or if they would be at different position in the list, something like this:
here route 2nd and 3rd, or 2nd and fifth list item
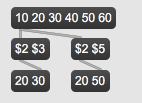
in more complex situation like if one wants to replace 3rd value of this index
with 2nd value from previous one etc, it is only a matter how to combine
messages.
All this works as long as coll indexes are consecutive 1,2,3,4,5,6 ...
if they are not, one would have to recall them in a different way,
but that is another story.
God bless you. This is amazing. I think I see now, but I’ll have to put it into practice more. I’m coming to max from my excel… I think spreadsheets are so powerful and as soon as I discovered jit.cellblock and coll I felt like I unlocked a huge door. I’m still learning… but the dict objects look worth sitting down with. It’s very abstract for my little pea brain, but I feel like arranging samples(I like “segments”) of audio files using these techniques is weirdly overlooked. If you or anyone else has any suggestions about literature… specifically about using data arrays to organize and arrange segments of audio files I’d be super interested. Damn dude this forum rocks!