
fexpr~ to gen translation

is there an example of the below in Gen?
x = sample-by-sample evaluation of expressions
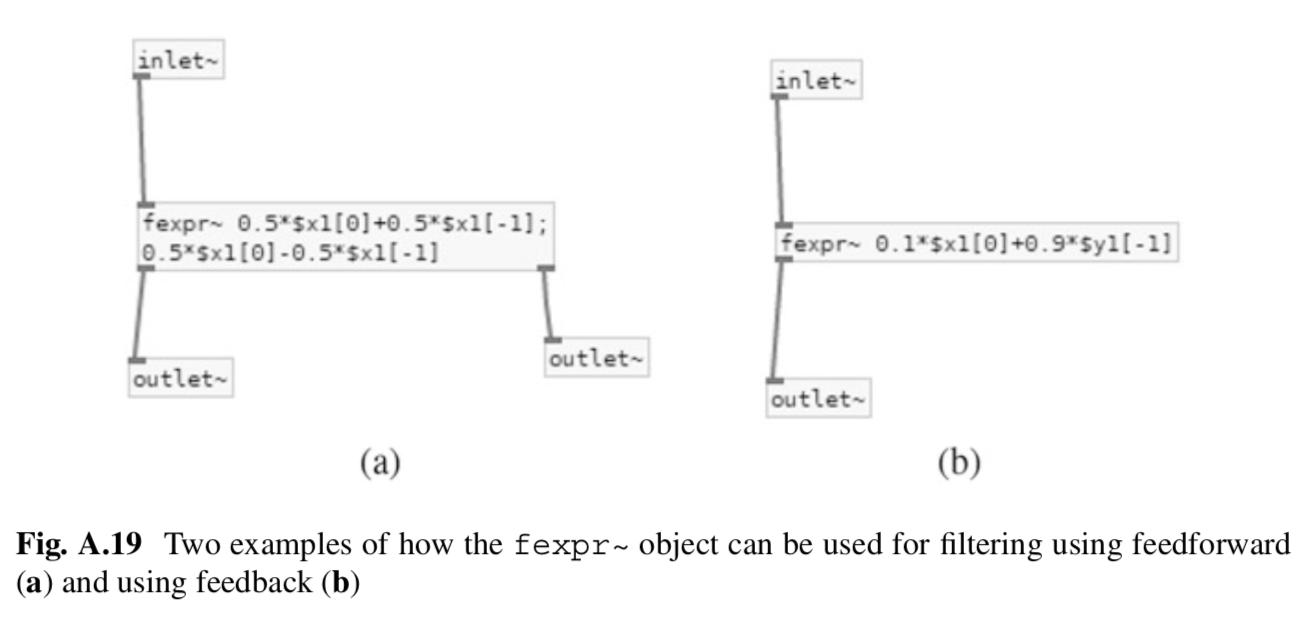

I'm presuming from the caption that $x1[0] means the current input sample, and $x1[-1] means the previous input sample; and $y1[-1] means the previous output sample.
In gen~ we can use [history] to get the value of the prior sample. If gen~ `in1` gives $x1[0], then `in1`->`history` gives $x1[-1]. Similarly, whatever is being set to the gen~ `out`, also feed that to a `history` and you'll get $y1[-1].
In genexpr (codebox), (a) is:
History x1;
out1 = 0.5*in1 + 0.5*x1;
out2 = 0.5*in1 - 0.5*x1;
x1 = in1; // update at end of code box to ensure the 1 sample delay.
and (b) is:
History y1;
out1 = 0.5*in1 + 0.5*y1;
y1 = out1; // update at end of code box to ensure the 1 sample delay.
This stuff is all pretty basic form for developing filters. Take a look at the gen~ biquad example, which uses both two feedforward and two feedback paths (that's what a biquad is).
The general form is $xN refers to [in N] (or `inN` in codebox), $yN refers to [out N] (or `outN` in codebox). The [0] means current value; [-1] means the value passed through a 1 sample delay via [history] (AKA the Z^-1 operation). To get longer histories than [-1], use a [delay].
Many thanks Graham, that was incredibly useful to get explained.
I'm working towards trying to make an LPC type breakpoint filter (alla AudioSculpt) slowly – and hoping I can do this with Gen. I just haven't seen LPC done in Gen, so I'm going from this diagram as a starting point:
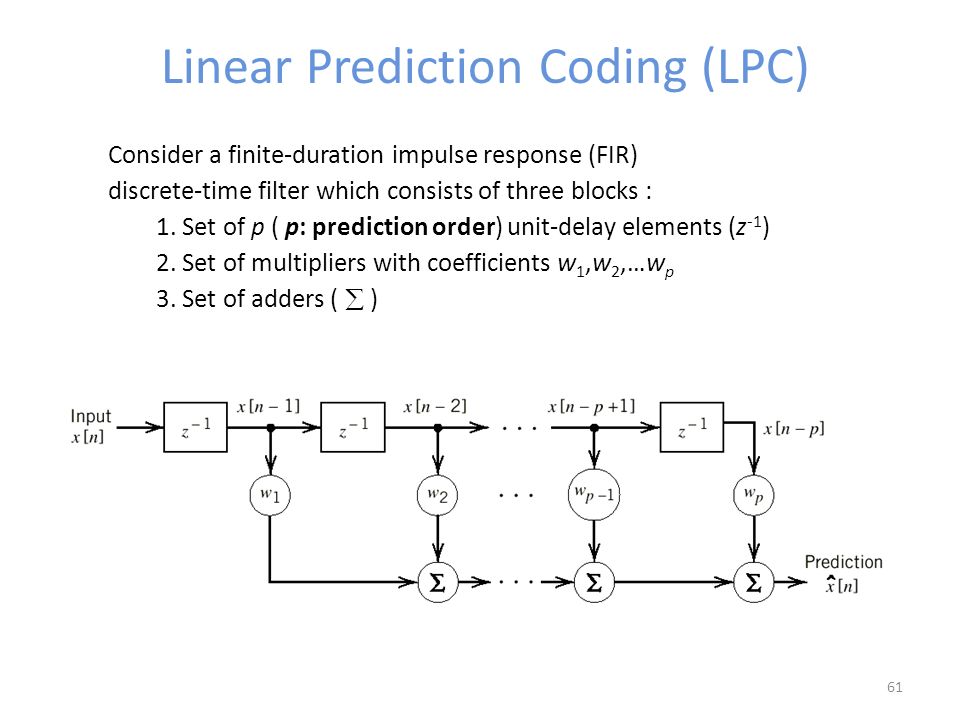

that block-diagram looked like fun so i thought i'd try to do a 16-stage one, just patching-style in gen~(no codebox)... using a multislider to set the weights all-at-once here(plus crossfading through a history of them to tame clicks/pops at changes)...
i dunno if it's correct, but it sounds interesting:
(a codebox-version would help modularize to extend to larger sets more easily... i'm also wondering if it should maybe be done with a 'data' object... used instead of the 'history'-series(?))
a slight evolution(to take care of the clicks/pops when setting weights, i created a smooth crossfade out of the weights-history 😋):

Well, that's truly awesome, ... and maybe someday I will understand the principles behind it thx Raja
my pleasure... actually you got me thinking i could maybe comment it better, here's comments within the gen~ patcher, to show where the patch coincides with the picture/diagram that SmokeDoepferEveryDay posted above:
Yes, ... thanks for taking the time,.... this helps...
Whenever you are deciding to teach max stuff the cool way, ( it certainly doesn't have to be this patreon wormhole^^), I will be participating... all the best
Woah, R∆J∆ !!
I was not expecting this!? :D
thankyou so much. This has saved me days/weeks/months of fiddling. Especially the (w1) (w2) (wp-1) etc
So this begs the question(s) if this were to be codebox and [data] gave something up to an order of 30 coeffs could I then parameterize with a BPF [function] or would it need some additional smoothing/windowing than the crossfading? probably right?
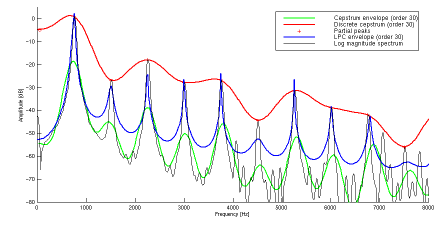
This was my ideal, to have a type of visualised LPC formant mask like in AS but with realtime input:
it was fun, happy to lend a hand :)
unfortunately, i'm not very woke about filter-design/topology itself 😅, i think if you have the right coefficients here(specific for FIR filters), you can do anything! 💪🙌😜
..just kidding, i don't actually know for sure, i might not understand your question, either:
i think the diagram which i turned to gen~ so far is just an FIR filter(i should've titled the gen~ subpatcher something more like 16-stage-FIR, too... oh well, my ignorance is now uploaded for posterity 😋😇 - whereas "LPC formant mask" involves something much more advanced i wouldn't know about... although the patch does come out sounding like a formant mask... is that what it is?! i didn't even know! 😆)
so if you have a BPF function in 30 coefficients for FIR, then it's probably no prob, otherwise, for IIR, you'd have to redo the gen~-based filter-topology to incorporate a feedback section:
https://circuitglobe.com/difference-between-fir-filter-and-iir-filter.html
i was just so intrigued by the diagram, because it illustrates something i've been noticing from this type of audio equation (and also in the way
neural-networks for AI work: https://en.wikipedia.org/wiki/Artificial_neural_network)
in all the equations you'll find: 'w1', 'w2', 'a1', 'a2', 'b1', 'b2', all symbolize something like a 'bias'(or 'weight') we multiply various stages of input/output-feedback by, to get the filter/analysis we want(even on a political/philosophical level, too: we tend to introduce bias in our perceptions of other people in order to try and get them to fit the world we wish to perceive 🤔🤯).
🤓
sorry if i completely misunderstand, hope that helps though 🍻
Hi folks,
I thought I posted a reply further up but it didn't get through (mistakenly replied to the email notification ugh):
"By the diagram that looks totally doable. It is essentially convolution of the input with the list of weights, which means, the list of weights make a FIR (finite impulse response). There is an FIR example included in Max, not sure if that helps though."
The FIR example is "gen~.buffir.maxpat". It uses a Delay rather than a chain of History nodes for the summation (since this is a linear sequence of single-sample history nodes it works out), and a Buffer rather than Data for the weights (i.e. the impulse response) so that they can be configured outside of gen~. But, functionally the same, I believe.
This is time-domain implementation of convolution, which works well so long as the FIR isn't too long (not too many w's). "Too long" is approximately comparable to whatever your block size is, and otherwise dependent on CPU of course. 128 seems like a reasonable number. Anything significantly bigger than that, and you'd want to turn to spectral domain processing (FFT).
(somewhere I also have a patch that computes FIR's from FFTs, I'll have to find that...)
Though, it's tempting to wonder if there isn't a middle ground between, where some degree of input compression happens allowing a shorter IR -- especially if you don't need all the high frequency information. Or, perhaps some kind of wavelet approach. It depends on what you want to use the output for I guess.
@👽R∆J∆ yes indeed there's some similarity with artifiical neural nets; though they would be more typically like a collection of nodes of the form "mixer + offset generator + waveshaper", quite often the input layer is the equivalent of the recent content of a delay line.
What's missing then is the backpropagation process (the part where it learns the weights), which would adjust the mixer weights + offset of each node according to the prediction error at the end, working backwards to the input. I've been wanting to build a little example of that in gen~ for a while, maybe now's the time.
This is time-domain implementation of convolution
ah, sweet jeebus! i didn't even realize 🤦♂️ (got me some rereading to do)
"mixer + offset generator + waveshaper"
ha, interesting, i was looking at 'activation functions'(tanh, sigmoid, relu, etc.), they seem like 'waveshaper's in many ways(they serve the same basic purpose?)
https://deepai.org/machine-learning-glossary-and-terms/sigmoid-function
i built 'logistic_sigmoid' in gen~ awhile back, it constrains things within the 0.-1. range(i see why tanh might be better for audio), i guess it's kinda useful for audio in other ways, though:
(☝️apologies, my mind wanders to so many tangents 😅)
Thanks for taking the time to explain, Graham! 🙏 Truly appreciated 🙌
i'm exploring this further, and ended up making an FIR-delay-based distortion:
(basic description: it uses a delayed version of the input as coefficients for the FIR, and allows for a variable-order of FIR... also has added overdub/feedback param... by keeping everything in the signal realm, i could add several rand~ objects to drive continuous real-time modulation of the distortion params)
let me know if i'm getting any part of the FIR wrong.
i guess we can already do this with buffir~ 😂
(but it's fun to play/design around this idea at the sample-level in gen~... i think i might 'intuitively' grasp the math better this way... or at the very least, grasp what i can do with it)
thanks guys this was all immensely helpful and has me gradually trying to implement a AudioSculpt style frequency masking LPC in Max (albeit very gradually at my pace of understanding)
R∆J∆ would have loved to seen what you were cooking up with the "FIR-delay-based distortion" :D sounds amazing!
would have loved to seen what you were cooking up with the "FIR-delay-based distortion"
it was actually a not-so-great experiment so i removed it: i realized after posting that it's basically the same as Graham's patch above(which is the gen~.buffir.maxpat example from the gen~ examples folder), except instead of impulses, i drew shapes into a multislider to write into the buffer, much like my first patch but extended to 128 samples(and i didn't have the lo, mid, hi selection, just one buffer~). once i looked at the example Graham posted, i realized, using transients like in there gives a more detailed/specific form of control(my distortion was a bit unwieldy).
thanks for this great thread, though! if you remember/feel-like-it, keep us updated as you make headway on the formant-mask-LPC 🍻
@Graham
no worries if you're too busy, but if you find the time and the patch, would love to see this one:
(somewhere I also have a patch that computes FIR's from FFTs, I'll have to find that...)
Had a dig around and I can't find it. I did find a few interesting things though, including an example of passing audio through Jitter to do FFT there, and back (not sure why that's useful), an example of using FFTs to create bandlimited banks of wavetables, and a slightly modified version of the FIR generator for the purposes of up/down sampling. I'll have to see how well these actually work and share if they do.
no worries, but if you find the time and feel those others are worth sharing(particularly the "FFTs to create bandlimited banks of wavetables" and "FIR generator for the purposes of up/down sampling"... the Jitter FFT would be great, too, i've seen Jack Walters and Jean-Francois Charles put out some papers on that already though: https://cycling74.com/projects/the-fast-fourier-transform-and-spectral-manipulation-in-maxmsp-and-jitter-beta) i'm always interested 🤓