
Max Device terribly slow inside Live

I nearly finished my max device and now for one of the last steps i put it into a ableton audio device.
Inside the max editor it runs good, but inside live i get a cpu load of 150% and that is dead end ;)
There is not too much happening, basically i have 12 mc.send~ / receive~ pairs, 10 instances of fab eq and 11 audio buffers, (delay~) about 15-20 seconds each.
EDIT: Haha that is wrong. it is more "per channel" and hence is to be multiplied by 11...
Still i got a cpu load of factor 2-3 inside live compared to max editor.
Any experiences? is it normal that live performs so badly compared to the max editor? When i open max editor in live it runs faster but still i get dropouts which does not occur in max editor. :(

hmm, that's odd, in my (extremely) limited M4L experience I had much worse performance when the editor was open. I'm interested to hear what's up from someone who knows this stuff.
really? thats really odd. i made a few devices now and the difference was always heavy...editor was much faster. now this time the devic is useless in ableton in the current state :p
My experience was with midi data though, not audio, so I guess it works differently in M4L.

Well, you are running that (large) pile of stuff in the Live application's low-priority queue as opposed to running in plain old Max, for starters.
You also haven't mentioned how much UI eye candy (another CPU burner) you've got going.
Perhaps a troll through the Forums in search of optimization tips would help
well i have quite sophistic graphics... but they are only active during animation phase.
i found that 95% of the cpu load is generated by the patcher including the sends and receives.... i will try to reduce the buffer size for the latency compensation... i guess the max buffer size can not be set with a message this is stupid. i calcualted the worst case i have. with fab eq in max phase linear mode there is 1.5 sec of latency and i can place up to 11 fab eqs in sequency resulting in a buffersize of 1..5* 10= ~15 secs .
but i think the buffer size is not the problem i guess its the send~ and receive. i have in total 11*11 + 2 = 123 send~ and receive~ pairs.... i guess this is the problem.

i bet its the vst plug-ins, which, hosted in max/msp, usually need far more CPU compared to what you are used to see in other hosts.
120 send/receive signal connections is something you can normally do on a computer with 150Mhz.
is there a specific reason why you dont use custom filters?
and did i mention already that many here would appreciate if you share your final version of mgraphics interface? ;)
this is how it looks like, and you see why i need these lots of sends~ and receives...
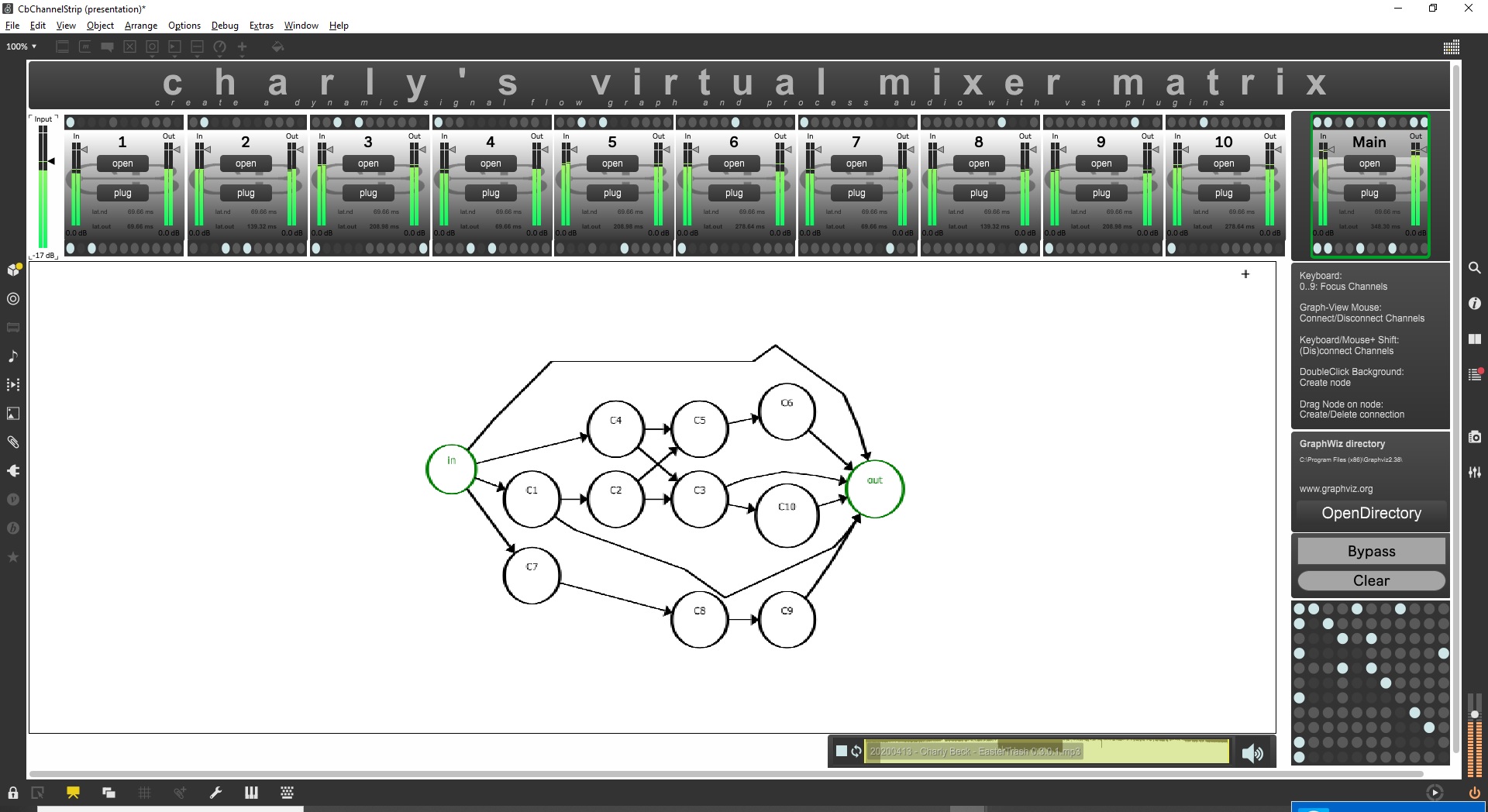
yes there is a specific reason for not using custom filters because the eqs are just for testing the latency i want to be able to load any vst plugin... nd 11 fab eqs are not much....
roman: Ok. that numbers with 120 sends/receive on 150mhz cpu make me think...
i need to check what causes this heavy cpu load by removing the stuff step by step... maybe it is some bug by me..
if you really only use it to connect two things, then those who said it is a regular connection are completely right.
i would use something like
selector 10
matrix 1 9
matrix 9 8
matrix 8 7
matrix 7 6
matrix 6 5
matrix 5 4
matrix 4 3
matrix 3 2
that saves a few connections.
you dont need to be prepared for the path 3-7-3-7-8-7 when you dont allow feedback loops. :)
i'm not sure if i understand your approach.
actually i don't connect just two things. i connect every node with every node....
though a routing in graph G1:
1=>2
2=>1
is forbidden and you could say routing 2=>1 is not needed, a routing for graph G2:
1=>3
2=>1
is indeed possible... so the routing 2=>1 is required in generall, although in the specific graph G1 it is not used.
you see, i do not build the routings depending on the graph. j could do this by creating max objects and connect them but that is a different aproach. i have a static max routing that can be configured to realize any graph possible.
maybe i'm too lost in my current asap-design to understand how your graph setup above shall work maybe give me a little hint. how are the matrixes connected? how do you enable/disable a particular routing?
i will describe in detail how it works currently:
in my approach there is a input matrix [11, 1] that mixes all inputs together. then i have a vst plugin that gets fed by the input matrix. then it goes to an output matrix [1, 11] that can send to any output(s).these two matrix~ exist for every channel. confguring is done by manipulating the input and the output matrix of every channel.
that could be put to pseudo code ala
perChannel: receive~[n] -> matrix~[11, 1] -> vst~ -> matrix[1, 11] -> send~[n]
so the routings in graph G3:
0=>1
1=>2
2=>0
is done by setting
c[1].InputMatrix = [1,0,0]
c[1].OutputMatrix= [0,0,1]
c[2].InputMatrix=[0,1,0]
c[2].OutputMatrix=[1,0,0]
the main input/output c[0] is treated specially though the iomatrix for c0 is
c[0].InputMatrix=[0,0,1]
c[2].OutputMatrix=[0,1,0]
the trick is just that c[0].Output[0] is connected to the main output Co0 rather than to the internal routing C0. Corresponding to that the input[0] of c[0] does not get it's signal from the internal routing C0 but from the main input Ci0.
so in the above matrix the signal flows like:
Ci0=>C1=>C2=>C0->Co0
that thing with the special handling of the first dot in the matrix is quite confusing... but to realize what happens, see that setting the first dot in the matrixctrl (top left) does not result in a feedback loop but just maps main input to main output directly. so
enabled[x,x] = x== 0
this is a static rule for the matrix. the rest of the enabled states for
enabled[x,y] where x!= y
is done dynamically depending on the setting of the other dots.
this is done in this patcher which exist for every channel. so in my current patch which supports 11 channels the patcher exists 11 times. the main in/out handling is done by [p ReceiveMain] p[MainOutOut]
ps: here is the method Matrix.GetFeedbackLoops internal IEnumerable<int[]> GetFeedbackLoops(int aColumn, int aRow)
{
var aFeedbackLoops = new List<int[]>();
foreach (var aCurrRow in Enumerable.Range(0, this.IoCount))
{
this.GetFeedbackLoops(aColumn, aRow, aCurrRow,
new List<int>(), aFeedbackLoops);
}
return aFeedbackLoops.ToArray();
} private void GetFeedbackLoops(int aColumn,
int aRow,
int aCurrRow,
List<int> aPath,
List<int[]> aFeedbackLoops
)
{
foreach (var aCurrCol in Enumerable.Range(0, this.IoCount))
{
if (aCurrCol == 0)
{
// out[0] is main out.
// => Mapping to out[0] always possible.
}
else if ((aRow == aCurrRow && aCurrCol == aColumn)
|| this[aCurrCol, aCurrRow])
{
if (aPath.Contains(aCurrCol))
{
aFeedbackLoops.Add(aPath.ToArray());
}
else
{
aPath.Add(aCurrCol);
this.GetFeedbackLoops(aColumn,
aRow,
aCurrCol,
aPath,
aFeedbackLoops);
aPath.RemoveAt(aPath.Count - 1);
}
}
}
}
if you dont allow feedback loops, you do never need to connect any node to any node, because the maximum structure you can have is a tree. ;)
as soon as IN goes to 1, 2, and 3, and 2 goes to 3, too, you can no longer connect 3 to 2.
i am aware that it doesnt make a big difference when your routing happens in a compiled external, but if it is MSP, you could halven that magic number of 123 signal connections.
my objects above (if i didnt make an error) are simply a representation of all possible algorithms - without assigning the nodes to the actual VST instance numbers.
aha, you are using matrix AND s/r. :)
i am now outing myself as optimisation idiot; but i would do these latency compensation things only optional for the rare cases where a plug-in actually has latency.
p.s.:
and if you dont mind interrupting the audio when the configuration changes, you could probably save some 80% CPU by using [forward] or even non-MSP [gate]s to connect nodes.
that would be even more economic than using matrix~ - while still not needing to script, javascript, use poly~, or send "enable" messages around.
signal router, without any signal connections other than the signal connections you want to route.
#P window setfont "Sans Serif" 9.;
#P user number~ 83 424 135 439 9 139 3 2 0. 0. 0 0. 250 0. 0 0 0 221 221 221 222 222 222 0 0 0;
#P window linecount 1;
#P newex 83 385 50 9109513 *~ 1.;
#P newex 258 155 86 9109513 t 1 l 0;
#P newex 251 111 86 9109513 prepend send;
#P message 300 75 50 9109513 nowhere;
#P message 238 65 50 9109513 FX1;
#P newex 83 330 86 9109513 receive FX1;
#P toggle 348 241 15 0;
#P newex 296 274 86 9109513 dac~;
#P user number~ 95 56 147 71 9 139 3 1 0. 0. 0 1.41 250 0. 0 0 0 221 221 221 222 222 222 0 0 0;
#P newex 75 192 86 9109513 forward nowhere;
#P comment 203 44 192 9109513 connect this node to node $1;
#P connect 5 0 10 0;
#P connect 10 0 11 0;
#P connect 2 0 1 0;
#P connect 9 1 1 0;
#P connect 8 0 1 0;
#P connect 8 0 9 0;
#P connect 9 0 3 0;
#P connect 9 2 3 0;
#P connect 6 0 8 0;
#P connect 7 0 8 0;
#P connect 4 0 3 0;
#P window clipboard copycount 12;
in theory it is indeed possible to use less routings/latency optimization buffers. this i dont question.
but i say, if you want to implement this optimization you need to dynamically allocate the buffers and routings.
since i don't see a proper way to do this dynamic allocation in max-patcher i implemented it in a asap design (as static as possible) where all possible routings are present to allow runtime configuration without dynamic allocation/deallocation to realize any graph.
even in this asap design i could save nr_of_channels- 1 buffers / send-receive pairs because the routings n->n are the only routings which can never occur (except for channel 0-main in/out). but doing so would mean to adapt the patchers for each channel individually or have some more objects and index calculation i dodged this.
but if it's true what you stated, that 123 send/receives should be no problem for a 150 mhz cpu it does not make sense to optimize at this point.
calculating the max nr. of possible routings respecting the loopbacks would be interesting but overruns my maths capabilities yet it is not essential ;-)
using poly~ is another issue. i see it is a bit a missuse of the poly~ object and there was a discussion here in another thread about wether using mc.send~ and mc.receive~ inside poly is officially supported or just works by "good luck". This is why i stopped investigating into the poly~ approach.
so whats left is the asap design where you need at least n * n + 2 [- n + 1 ] instances of send/receive pairs for n = number of channels. the part [] is what i dodged so you get the magic number 11*11+2 = 123 for 11 channels. and this is indeed true for the asap design i chose for the stated reasons.
i would prefer to extend my clr adapter to allow to create, delete and patch max objects from c# code dynamically. but there are some stupid barriers doing this. starting by the lack of a complete meta description yet documentation of the parameters for the newex calls. finding the parameter sequence for each class by testing it out is not a way i wanna go. and i saw it seems not possible to define the scripting name for each class so how to delete the dynamically created objects when the user selects a new graph definition?
so respecting this circumstances, this is why i wanna investigate in implementing the routings and buffers for latency compensation in c/c++. yet a nice practice to get familar with audio processing :-) and then everything is dynamic and only necessarry buffers/routings are allocated.
from the patcher you sent i see how you wanna use forward/send to do the routings. but there is nothing that gives me an idea of how you wanna patch the n channels and switch configuration for different graphs.
about the difference of a tree to a directed graph i'm not sure. for me a node in a tree only can have 1 parent and subnodes have no connection to the parent's sibling nodes.
in a graph a node can have n inputs and n outputs. also with excluding feedback loops this is true for the directed graph i'm working with...
in the encoder models in direct show this structure is also called a "graph" although it's "just" a directed graph.... but never a just a tree.... just to have the definitions clear.
maybe "tree" is not the correct word for what i mean, but the sum of all possible connections for IN, 1-10 , OUT, and no feedback allowed is not very big.
your last picture above is a very good "average use case" i think, and that is why i am dropping a counter approach to yours.
to connect nodes liks this, you normally do not need any audio objects, you only need to have up to (yeah i havent calculated the max yet either) signal connections, and they should not have any CPU hunger worth mentioning.
you have a lot of knowledge and experience about how to build a solution impressivly fast, and so you immediately started to work on a very high abstraction level instead of translating your machine model to "simple max" first and then maybe extend it later, like most maxers would do.
regarding the use of mc.
for a routing matrix, my answer is the chaos theorem:
how many connections will one averagely make when using the app? let´s say you will averagely use 7 plug-ins and have 4 of them somewhere in parallel. that makes 12-15 connections. furthermore, 95% of the VST plug-ins do not have latency.
and for that average use case you implemented more than 3000 audio signals here and let them run all the time.
you probably already planned to remove your 275 meter~ objects in the final version, but this is not the only thing i would remove. :)
anyone able to calculate how many possible connections such a matrix can have?
isnt it 9+8+7+6+5+4+3+2+1 ? +10 from the in and +10 to the out?
actually seems to be true... maybe it is that easy. but this number requires dynamic allocation, doesn't it?
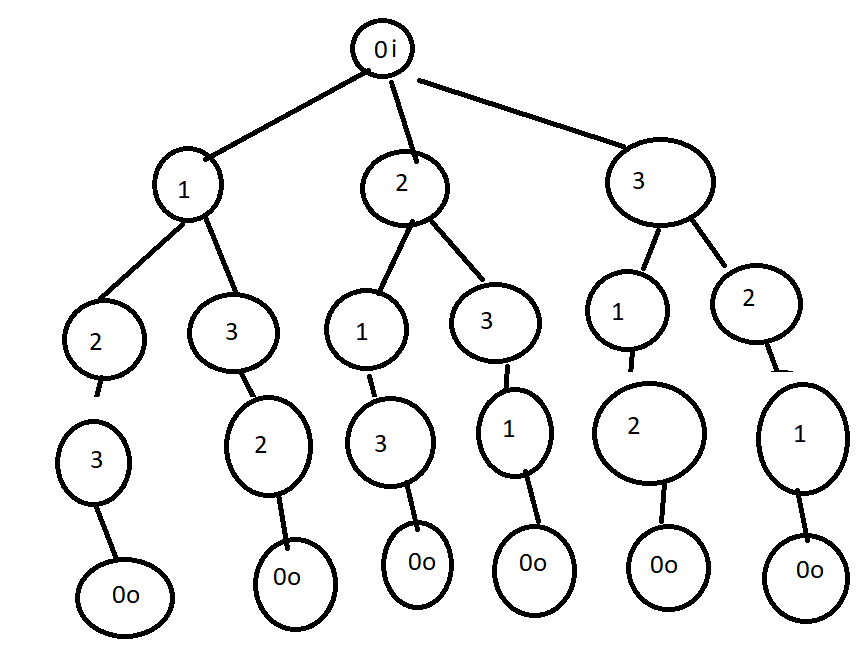
this is what you mean? (for 3x3 matrix)
still the node 1 for example occurs severl times in the tree but you can only one instance of vst per number... this means you need to connect the nodes at runtime.... hm...
regarding your answer: The meter objects are just for debugging.... i hoped that it would not make any performance load as they are not viewed but now that i understand the max internals better i see it surely will...
the "problem" with the tree above is, that it only shows possible signal pathts through the graph where in a particular graph there can be several paths active at once.... (and it does not treat these combinations at all)
example: so if you look at the left most path from top to bottom, this could be one graph 0i ->1->2->3->0o. but another graph can also contain the routing 0i ->2->3->0o at the same time. This is why it becomes more complex than what is obvious when looking at that tree.... also "shortcuts" like 0i->0o or 01->2->0o are not included in this tree.
i a have a static number of vst~ plugins that is equal to the number of channels. the number of edges between the nodes is the big question.... and also how many delay~s you need. because you need the delay at the input of each node.... for each possible input. (yes and only if the path has latency at the particular input)
i'm not good in maths.. but it seems to be more a fibunaczi problem than just adding 3+2+1+x
surely in a dynamic design it will much less connections and nodes than in a asap design... yet i don't undertand how to impleemnt this in max...
nevertheless.... hard-wiring the vst~ and delay~ objects at runtime instead of using send~ receive~ and matrix~ seems to be an interesting approach and good idea to save cpu load.... and we don't need to be able to calculate the number of max connections to solve this.... ;-)
1 allocation)
yes, instances 1, 2, 3 in the hardwired model will have to be mapped to the actual VST modules you choose.
2 picture)
haha, no, thats not what i meant (like i said i was wrong about "tree") - but this is also an interesting idea.
what i mean is...
- you have these VST modules "1-10"
- then in your routing matrix you treat them as "A-J"
- the algo the user creates in the GUI will be nothing but a list of connections, aka A-B, B-C, C-D, A-C, A-OUT, C-OUT....
- now you create the connections and remap A-J to 1-10.
3 number of algos)
"i'm not good in maths.. but it seems to be more a fibunaczi problem than just adding 3+2+1+x"
my "tree" code above was based on this idea:
if you connect IN to C3, nothing else can be connected to C3
since you just used C3, you now only have 9 targets left
if you now connect C3 to C4, from C4 there are only 8 targets left.
you can still connect IN to C4 though.
okay, i see where i made an error, it is not complete. :)
4 latency compensation)
it is clear that if you want to include full PDC, then it must be done for every node and not only in the summing mixer, or it wont work for
C3->C4->C9
C3->C5->C9
but in your current implementation you always delay all 11 mc. channels, dont you? i somehow feel one should do it only to the active channels (i am not sure why you used mc. anyway, but that´s another story)
it would be cool if you find a way to make the software understand the algo and only insert an "additive" delay at the positions where needed.
for the parallel aligning of channels which dont touch each other, you could then do the rest in the OUT mixer.
i think the key could be to make the app aware of "rows and colums" in the algo. then if a plug-in has latency, all others in the same column are to be delayed.
5 max4live)
one new topic.
i just noticed that unfortunately in ableton you can of course not recompile the DSP chain, which is required for my "no DSP objects at all" method. :(
but i will still post you an example of one of my old plug-in matrixes after the weekend that you can see it in action.
ok. yes, i think hardwiring the stuff at runtime is also what you are talking about and i will investigate in this.
i think the latency compensation is correct as it is. for each channel has inputs for every channel the delay is located at this input of the node. on the blogger page i made a video which shows some demo node latency. this is one value per node. i realized later that the delay(latency compensation value) is another value and you have several of them in each node:
Graph:
1->3
2->3
i realized that after i set latencycompensation = latency_max of previous nodes which delays the signal even more :D no - it must work like this:
imagine latency=channelnr. then you have at node 3 two input signals. one with latency 1, the other with latency 2. Now you need to calculate the maximum value and subtract the latency of the input signal. so you get a latencycompnsation of
l3_1 = 2-1 = 1
l3_2=2-2 = 0
that is how it should work in any graph.
so i have delays on each input channel on each node but the delay is set to 0 if it is so. i was assuming the delay will not cause overhead when it is set to 0 but this is also a thing which should be verified.
i will try to create the delays dynamically in the next step with the maxdelay=currentdelay. that is better. currently i set a very high maxdelay value and however how high it is - it will be a restriction and the graph will output bullshit if a node needs more delay. (ok it is very unlikely a user puts 10 eqs with max linear phase mode in a chain but nevertheless i don't like something like thas. murphy's law tells that whatever causes an error will become real at some point ;-) And i think murphy's law is fundamental for sw development haha... it has happened too often :D
about recompiling the dsp chain: I don't see where this happens in max and not happens in live and why it is necessarry. what happens during compilation of the dsp chain and why it is required?
there are two ways how to set up latency compensation in a normal channel mixer.
either you accumulate everything from where it is caused to the end, then find the max of all channels and do max minus own latency to set the delays of the other channels.
the other option is to set an arbitrary buffer lenght as default, then you can substract from that value.
the issue with a patching matrix is that it has a more complicated structure compared to a channel mixer, and i am afraid that you are right that there is no other option than to do it in every node. (because every node could have another node running parallel)
about the "how" i dont have a ready solution for your matrix but it is interesting enough for me to dive in.
delay~ 0 needs as much CPU cycles as delay 100000.
recompiling the dsp chain would be needed to use [forward] as your audio router as seen in May 22 2020 | 2:29 am
while it is the most elegant and lightweight design for situations where restarting audio is not a problem, things like [forward] or [prepend foo]-[gate] for signals is not a solution for max4live, pluggo, or for an application which is used for live audio.
under the hood these forward/prepend tricks are probably quite similar to scripting connections. (just more elegant. :) )
so... [maxtrix~] would be your start for experimenting with a"hardwired version."
well i now have implemented it. everything gets hard wired whenever the graph or the latency changes. and the cpu load in ableton live goes from 160% to 20%. And these 20% are fix costs for the refreshing of the plugin latency and/or some plugins i loaded.
Actually it seems like the mc connections don't cause any cpu load at all. When i make up a maximum number of routings it still has 20%.
btw - i don't use any matrix~ now.
now that was a successfull optimization! :)
Still need to check phasing. Because i guess the mc objects will have a latency of 1 sample when you connect severeal mc cables in the same input.... (?)