
Separating Stereo Segments – possible?

Is it possible to isolate/separate segments of a stereo signal?
Let's say we divide the stereo field into 6 segments. Based on a 180 degree model for the whole field, 6 segments have 30 degree each. How may it be possible to isolate each segment and get 6 audio channels to process them independently? It will of course be fuzzy, but I wonder if it even can be done.
I tried with the Ambisonic package for Max/MSP and got just weird separations. But I do not understand this tools, I think I cannot configure them properly. Therefore I don't now if they could do it. As a second approach, I tried to pan and phase-invert the virtual segments. This, I believe, won't do it.
Any ideas?

i do that with 5 channels and it is relatively simple.
but there are different options and it is hard to say which one would be the most generic or most straight forward.
in a first step you would just mix a bit of the right channel to the left channel in order to get channel number 2 out of 5.
but you can go further and distribute the input material on multiple channels using the difference in power history between left and right (and eventually the difference in power history between mid and side in addition)
-110
I see, if I understand you right, you take more or less what you can get with LR and MS.
What do you mean with "power history"?
I thought, that the Ambisonics system could be fed by 2 sources (stereo) and distribute the whole thing to 6 or 8 channels, representing evenly spaced stereo positions. But maybe the stereo impression and the various directions are just psychoacoustic effects, not possible to work with.
ambisonics & co mostly deal with speakers - if your only aim is only to process audio on parallel channels the distribution onto these channels is normally much simpler, sometimes just "straight" :) linear.
when using speakers you can think of the stereo signal you are going to distribute on many speaker as two mono sources to get it simpler.
the weighting of the gains is then a matter if how the setup looks like (circular, half circle, one line, ...).
however, in both cases just try what happens when you use the following setup for stereo to "stereo 8".
C#1 (7/7*L + 0/7*R)
C#2 (6/7*L + 1/7*R)
C#3 (5/7*L + 2/7*R)
C#4 (4/7*L + 3/7*R)
C#5 (3/7*L + 4/7*R)
C#6 (2/7*L + 5/7*R)
C#7 (1/7*L + 6/7*R)
C#8 (0/7*L + 7/7*R)
this is about what the DDMF directional EQ plug-in does.
in case we are talking about a quarter circle of 8 speakers in an unechoic room, compare this against
C#1 (7/7*L + 0/7*R)
C#8 (0/7*L + 7/7*R)
it should be almost the same, just a bit louder.
with power history i mean measuring it using average or so, and use this control signal to exaggerate the channel separation.
Thank you for this example, very interesting!
It is a bit beyond my scope. I tried connecting two audio channels (stereo file) instead of your noise~ and pink~ but I think that was wrong ;-)
In the meantime I found a software that has such a pan isolation included, it is called "Capo" and mainly for transcription, learning/analyzing songs etc. There you load a file, set the pan position, and width you are interested in and get just this part of the stereo image. A rough frequency range can be set for refinement. With my synthetic test file (6 panned tones) it works perfectly, with a real audio recording of course not (artefacts). But basically it does what I try to achieve.
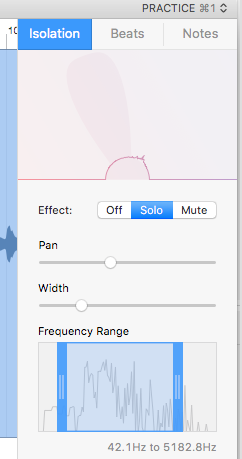
Is this what your method might be able to do, or something different?
as far as i understand the picture (you should really try to post a max patch and/or describe you aim) it is exactly what my patch does, just with the difference that mine has 8 outputs and the angle and width are therefore not dynamic.
and btw. i think that the "width" parameter in your picture doesnt really do anything when the input is a normal stereo stream. :)
Sorry for confusion. I removed my comment from the picture, maybe it is better understandable now.
Source is a stereo file. By "Solo" you want to hear only the selected panorama position. "Pan" selects the center of this position, "Width" adjusts the width of the segment you want to hear. Everything outside the chosen segment gets removed (!). Output is one channel.
I found just one plugin that splits by pan positions (MashTactic), but the algorithm in "Canto" delivers far better results. Maybe this guy is a genious, maybe we can re-engineer what he does.
———
I got your patch running and it distributes the panorama postions nicely across the 8 output channels. Finally I understand the technical problem and the problem in our communication: I do not want to distribute, I want to separate. Each channel should carry only the signal of the corresponding panorama position and nothing else.
Let me break it down to a smaller system with just 4 panorama positions:
A stereo signal with 4 panned tones: #1 left, #2 half-left, #3 half-right, #4 right.
How can I get tone #2 only, without the others?
if you ask like that, then the answer is "it is impossible".
a position of a sound source in a stereo panorama is an artificial construct. in fact it is never anything else but the same signal on both channels but with different gain.
in case the sound sources direction is broader than 0., this doesnt change a thing.
you create the positioning of a sound source by using eitehr 2 microphones, _panning a mono signal, or _balancing a stereo signal.
both pannning and balancing do not more and not less than changing the gain.
so if you want to reverse this process, all you have to analyze is gain.
will look into that coda thing tomorrow.
We are d'accord, it is impossible.
But what this guy made, is usable for audio processing under certain circumstances. Would be great to do it for audio streams in Max/MSP.
—
Capo, Canto, Coda – we are both inventing names, funny.
The name is CAPO
The software: http://supermegaultragroovy.com/products/capo/
In the press: http://www.soundonsound.com/news/capo-adds-neptune-isolation-engine?NewsID=19066
"The inner workings of the Neptune isolation engine are even more sophisticated, being able to determine the spread of energy across the stereo field."
...analysis of power history ;)
Ok, so it is not a thing I will learn during the next weeks on my own.
However, because of the mediocre audio quality of this damping-algorithm
it would be only usable for special cases ("Die Trauben sind eh sauer ..." ;-)
I think we are through. Thank you very much for your efforts,
your technique to distribute Stereo to Multichannel helped me a lot!

Quote: "if you ask like that, then the answer is "it is impossible"."
What a challenge, whenever someone says its impossible, my brain starts questioning that.
Main Difficulty in "real world" mixes. You don't know how it is recorded/mixed. If the mix was done with a pan. It might be possible. Make an FFT, compare different balance positions, Anything which appears only in the left, is clearly panned to the left, same for the right. Now you can test for different balance positions in between for a certain difference in level, place it to the according output...
If the recording was done with a stereo mic setup its much more difficult, as the angle might also be determined by delays between left and right channels, you get also all kinds of reverb leaking in. But it depends what you want to do with the result.
For ages there had been tools which try to separate the voice from the musical mix, simply by assuming the voice is panned to the center... But I don't know how this is done usually...
Another for us out of reach possibility, would be to teach a neural net to recognize different instruments in a mix and then separate them... Maybe Capo is doing something like that...
[Quote Stefan Tiedje] ... would be to teach a neural net to recognize different instruments in a mix and then separate them…
Should be possible. Humans and many animals can easily locate typical sounds in a cloud of noise. Maybe some modern household robot can already tell where instuments play in a stereo sound? I'll get my friend to ask her new vacuum cleaner :-)
" whenever someone says its impossible, my brain starts questioning that."
you´re absolutely right, that is how i once started the one other max project as well as real life projects such as social science jobs.
but i believe that the application he was asking for...
"Source is a stereo file. By "Solo" you want to hear only the selected panorama position. "Pan" selects the center of this position, "Width" adjusts the width of the segment you want to hear. Everything outside the chosen segment gets removed (!)"
... is at least very, very close at the borderline between possible and "not possible", dont you think? ;)
everything between L and R is nothing but a mix of L and R and the weighting of the mix is as linear as the virtual position. so you cant so more than do a simple comparison between L and R in all terms and fields currently known to audio analysis.
i dont see how a partial stream of "half left" position would differ from a partial stream of "half left" position "but broader". the rule of three suggests that these audio signals will be identically.
btw thats what the capos guys are also saying; i works best with 60ies recordings where music mixes were made quite simplistic.
and while it is true that you can built processes which can isolate voices (neuronaut showed us) in my opinion this has not much to do with the oroginal task of masking parts of the stereo field.
because 1. it will stop working when the flute suddenly moves from the center to hard kleft (and there are several beatles recording which do exactly that) and 2. you could as well do the same to a mono mix (which proves that it is not a matter of position in the stereo field.)
of course i only go contrary to help you inventing it.

yes if you knew the exact mic setup and response pattern (including polar response for different frequencies) you could probably reverse engineer source locations, especially if the mics were separated so delay information was present-- then it would be exactly the same process used by the brain, because that's all it does-- variations in delay difference and spectral difference represent relative radial position and distance from the subject-- but to do it with any success you'd need a neural net (ie artificial brain) to decode the information.
of course if the source is a multitrack ->mixdown with arbitrary panning then it's not going to work, just like the brain can't tell where a sound is "coming from" in the stereo field of a standard studio-produced recording-- in that sense production techniques like panning are a cultural artifact of a perceptual phenomenon (like cartoon-drawing is to vision)
but the first thing I would do is encode to mid-side, remove the mid to get rid of redundant information, decode back to LR and take it from there...
very good point FP, in acoustic recordings one can try to analyze the phase/delay vs other things.
but you should rethink your suggesting about removing the mid from an LR signal ;D
yes I'll take back that last sentence, way too simplistic
if you delete the center you´d change the original, and get silence when you isolate the center position :D
but any new form of analysing audio is always welcome. send it to me via snail mail if you can.