
heeeelp!!!!!!!!

Hi everyone.
I'm a beginner, but for a university exam I'd like to create a patch that can capture a live scream from a person and convert it into data that can be sent to TouchDesigner. Obviously, I'd like the sound to be cleaned up so that only the scream is captured and not other sounds like voices or footsteps. I've been going crazy for days because I've watched tutorial after tutorial, but they all use audio and not an ezadc (microphone). So far, I've only managed to connect the ezadc with meter and number, but I don't know how to proceed. My instructor recommended zmap, but I have no idea how to implement a patch like this.

There must be very sophisticated solutions. But you could start with this very simple one ?
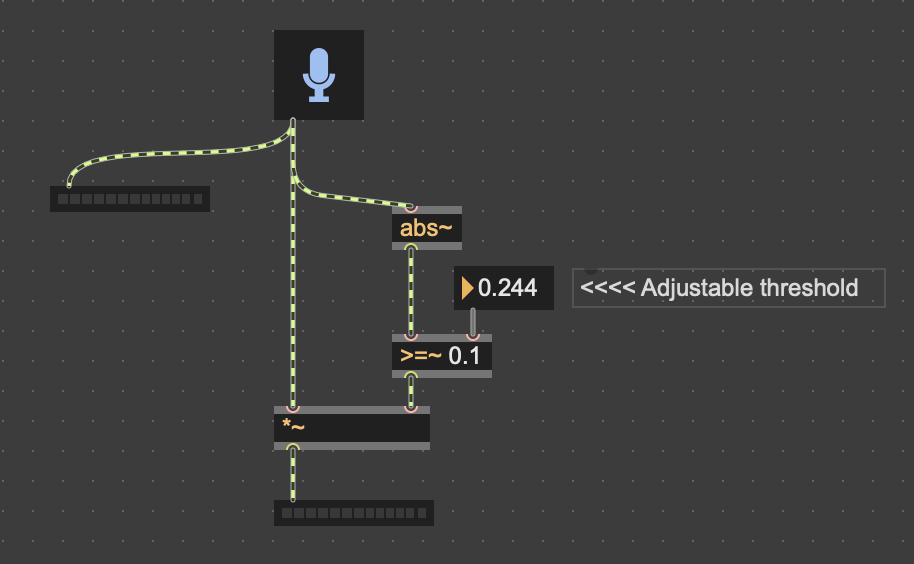
Edited.
I tried to insert it into Max, but I don't see anything and it doesn't generate any data; only the meter moves. The problem is that my teacher clearly wants a slightly more elaborate patch.
You may replace the last meter by [number~] to visualize corresponding signal values ?
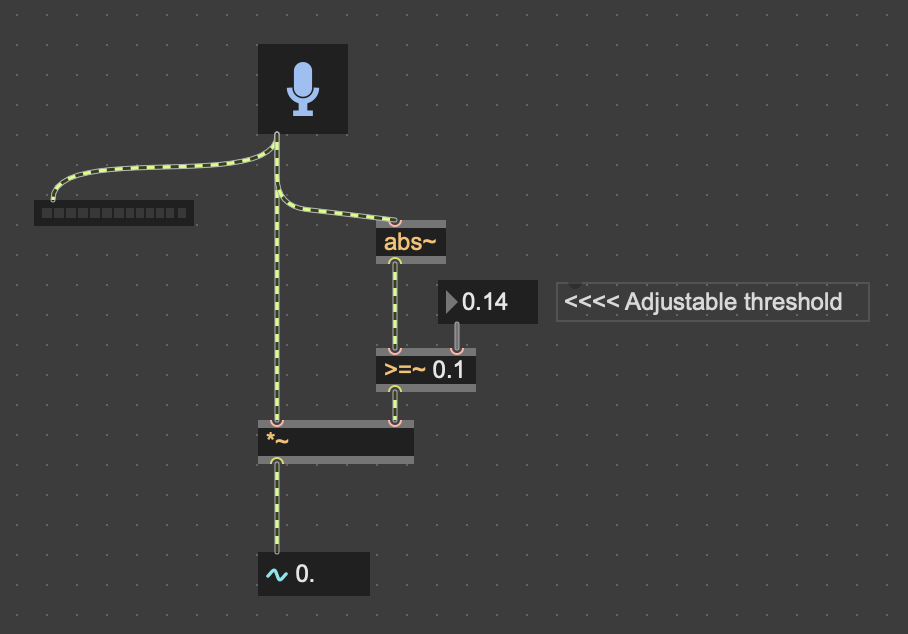
But of course, it's only a potential solution. It all depends on what your final project's objectives are ....
Edited.
Thank you so much for your patience. I don't know why it detects all sounds in this case. I'd like it to detect only the scream and exclude all other sounds, such as voices and footsteps. Therefore, it should only consider sounds with the highest amplitude. I'd then like that the sound be converted from analog to digital and the resulting data sent simultaneously to TouchDesigner.
it should only consider sounds with the highest amplitude.I don't believe there is a simple universal way of doing that. You have to calibrate what the threshold of "highest amplitude" is, in a given environment ? You can use the float number box for that.
I leave the question of the interface with TouchDesigner to others : I know nothing about it ;-).

You can not force a scream to be louder then a footstep,
what if one kicks the mic with the foot ?
you need controlable environment
which allows a scream at certain distance to the mic to be much louder then
environment noise. Like close distance scream into dynamic mic .
if you only measure level, and pass sort of level amplitude
after it passed a gate threshold, what then ?
a scream itself will not have much difference in amplitude,
which means you will be able to use it as a switch,
but not as a control value with a large range.
it is not considered that as a beginner you would use
complicated analyser to determine when someone screamed and
not talked loud.
here is what you could do :
1 measure level afer high or band pass filtering mic input
2 set threshold for the "scream"
3 scale threshold offset to max value as control data
4 send to TD using appropriate OSC string - port
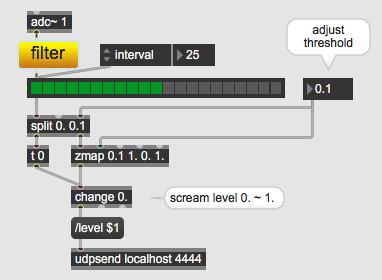

Welcome back! Ghost

Welcome back! Ghost
+1 The Ghostly Source!
https://cycling74.com/forums/heeeelp#reply-68bd8c9c318f119353f09a57 how can i create the message 'filter' ? i don't find it on max
thanks to all ghostbusters !

but I am not really back, just here and there...
And to "help screaming IDK" , why not walk a bit through Max tutorials dealing with audio filters ?
Also a bit of theory about where in freq spectrum one would expect human screaming to be prominent woud be helpful.
that yellow filter is only showing where to place it.
for a simplicity I would try reson~ with 200 - 500 Hz adjustable range
gain and Q - also adapt till you are satisfied.
higher the Q more gain it would need.
but before trying to copy the patch, read reson~ help file .
another screen shot
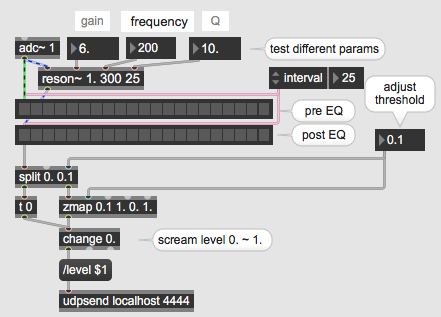
a bit of theory about where in freq spectrum one would expect human screaming to be prominent woud be helpful...
try reson~ with 200 - 500 Hz...
i think maybe should try a wider range of frequency: 150-1200Hz
the 'rough temporal modulation' of voice might be 30-150Hz as mentioned in this article:
but also in that article, see 'Figure 2.' where the spectrum shows the voice to dwell, while screaming "oh my god help me!", on average, between 500 to almost 5000Hz
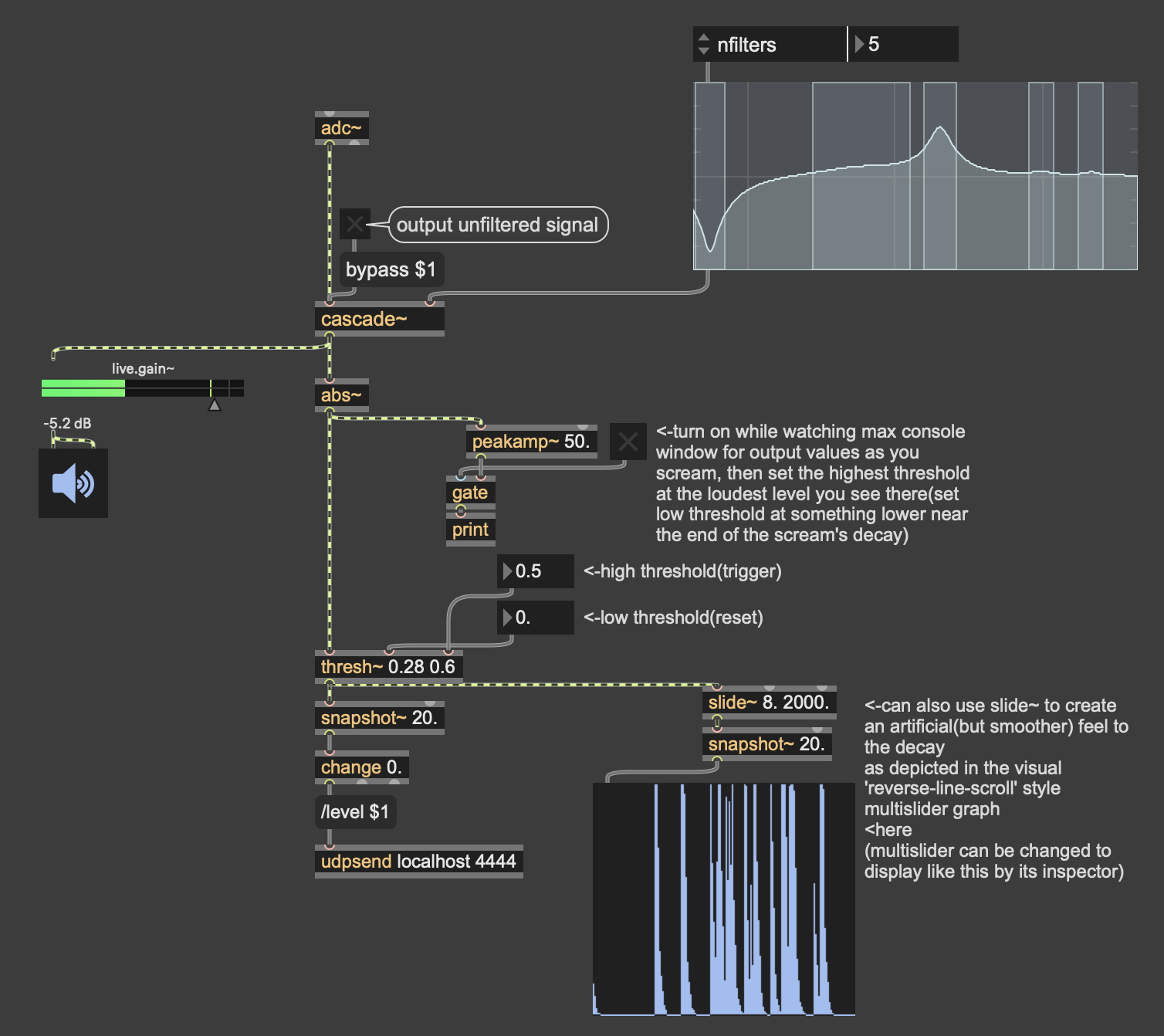
i think the main point that Ghost is making with filtering is to pre-process the voice before threshold detection(there's also the 'thresh~' object in case you need just a straight on/off signal while screaming, see helpfile for 'thresh~'), you can also see the 'cascade~' helpfile which includes a quick filtergraph~ UI, you can easily copy/paste to help you carve out the spectrum/EQ you want to hear, you could even do this with a vst~ object and load in your vst-plugin of choice to EQ and compress, etc., especially if the 'instructor' is so rudimentary as to merely suggest this:
My instructor recommended zmap
i don't like your instructor at all :(
if they are getting paid nothing, they are getting paid fairly :)
Thank you all so much! Sorry to bother you, but I have a few more questions, sorry. So, first of all, how do I adjust the threshold?
then, you said:
here's also the 'thresh~' object in case you need just a straight on/off signal while screaming, see helpfile for 'thresh~'), you can also see the 'cascade~' helpfile which includes a quick filtergraph~ UI, you can easily copy/paste to help you carve out the spectrum/EQ you want to hear, you could even do this with a vst~ object and load in your vst-plugin of choice to EQ and compress, etc.
So how can i implement this in my patch? which nodes have i to link to use these?
I'm really really sorry, but i don't understand this stuff and i saw videos and tutorials but nothing was good for my case...
thank you.
Trying to read the valuable article provided by 👽'TW∆S ∆LIENZ👽, I have difficulties understanding what "temporal modulation" means. Could anyone enlighten me ?

the main difference between a scream and talking or footsteps is the amplitude, power, and its quasi-periodic property.
it is possible to analyze any of these things using audio DSP, but it is not possible to learn audio DSP in 3 hours.
how can i implement this in my patch?
sorry, now i feel like i accidentally stepped all over Ghost's very considerate and detailed replies... but here's another (set of) approaches to explain the thresh~ usage, in particular:
any further questions about that patch can be answered by going through the official tutorials for Max/MSP located here, and to be clear, this is where your 'instructor' should've guided you to go in the first place:
from there you can see a heading known as "Examples and Tutorials" which takes you to the "Core Series", where all the experts you'll find online once began:
from there you would read 'Max Tutorials' first and foremost:
then 'MSP Tutorials' after:
_________________
@Sébastien Gay wrote:
I have difficulties understanding what "temporal modulation" means. Could anyone enlighten me ?
i barely understand it myself, but what i understood is simply best described by the terms Roman listed in his post directly after your post: applied 'temporally', in other words, not just amplitude fluctuations but also 'power' over time, and how that maintains a 'quasi-periodic' state(holds a certain volume over a specific window of time).
it has always confused me... i attended a lecture by Curtis Roads long ago, in it he described that, just like the human ear is centered around 1kHz so too is human speech, but a baby crying/screaming can reach upper-harmonics in the 9kHz range(he mentioned once reading about a study that seemed to imply that the harmonics in that range are extra harsh to the human ear due to human evolution, in particular, how parents/moms grew more attentive and alert to their young ones' cries for attention/help), from this he was attempting to explain to a fellow attendee, why females might be more sensitive in the higher frequency ranges than males... all this to say that the perceived loudness of voice also depends on age, sex, and even gender(because we all develop our voice over time influenced by perceived gender, as well).
apologies i'm not so expert or complete in recounting this stuff. but i'm just trying to describe how... we can't describe any of this completely in words or patches. we don't have an example of the person screaming, nor the mic they'll use, nor the space they'll be screaming in(?)
_________________
hope this can help, i will step out of this thread now, as i feel i've only brought confusion. apologies to everyone, again.
Just in case IDK finishes all the above examples and tutorials
here is a gen~ version use of slide with thresh levels
This example/tutorial is quite new from Philip Meyer
//
i feel i've only brought confusion. apologiesno sorry
very good example of timbre
which the human ear does a much better job at distinguishing between differences
while Max needs much more coercion - smiley face emoji
Thank you for the detailed response, 👽'TW∆S ∆LIENZ👽.