Several years ago, Darwin Grosse and I worked on a project that used optical flow to track people running around in circles to simulate the jog wheel on old analog video tape decks. As is often the case with many sensor projects, the raw data was really jumpy and jittery and required some serious sweetening and massaging. Darwin’s solution, much to my surprise, was the bucket object. It’s been a valuable tool in my Max swiss army knife ever since.
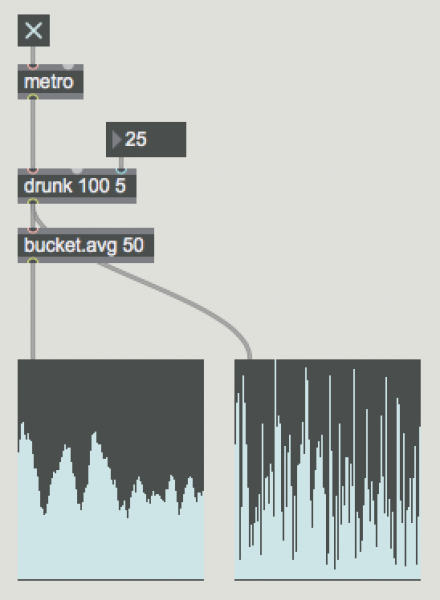
The bucket patch I use the most allows you to get a running average over some finite set of events (if you want a running average for an stream or unspecified set of values, you'd use the mean object). Here's an example that calculates the average of the last 8 floating point input values:
This technique is really useful, but can be a lot to patch when averaging a larger value set. The included bucket.avg abstraction included with the downloadable patches lets you type in the number of values you want to average and scripts the connections for you. Keep in mind that the zl sum object will default to a maximum list length of 256, so if you want a larger value, you’ll have to alter the zl object.
Here's the patch in action (make sure you have the bucket.avg abstraction in your search path):
Velocity and Acceleration
The bucket object is also computationally useful for calculating first and second derivatives for streams of data. The terms "first and second derivative" are math-speak for keeping track of:
the rate that things are changing (that's what velocity is - the rate of change in a value over time.)
the rate at which the rate that things is changing - that's what acceleration (the second derivative) is.
Here's how the patch looks:
A bucket for Symbols
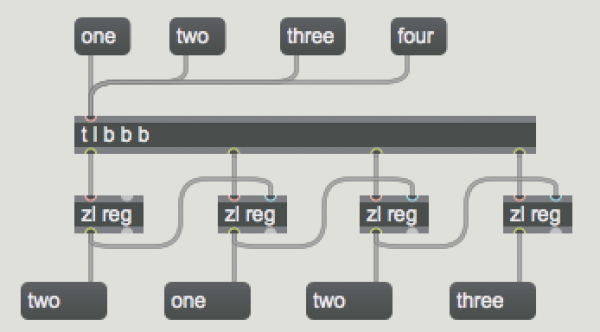
The bucket object is a little unusual in that you don't need to worry about using arguments to the object in order to have it work with floating point values. In fact, bucket is so useful that people often ask whether or not there's a Max object that is similar but will work with symbols or lists. While there isn't a specific object that works with symbols the way bucket does with numbers, here's a Max patch that does exactly that (and it helpfully outputs stuff in standard right-to-left order, too):
As with the first example, this can mean a lot of patching when you start making one for larger lists. The bucket.sym abstraction makes easy work of this - just type in the number of outlets you want as an argument (i.e., bucket.sym 4).
I hope you can see how I’ve come to rely on the bucket object, and how it has influenced me to make similar tools for other message types. If you have other uses for the bucket object, please jump onto the forum and share!
Thank you, Cory, especially for the "Velocity and Acceleration" and "A bucket for symbols" parts.
For the "Running Averages" I find it much easier to do this:
zl.stream X zl.sum / X.
No need for scripting and you can even change the number of samples to average dynamically by sending it to the stream and divider object's right inputs.
So simple! I think I'm going to go through all my sensor input patches and try out changing the smoothing method to this. And add in some acceleration based triggers. Brilliant. Thanks Cory.
Question, as I don't have max available right now to school myself: as far as I understand from the bucket reference, it doesn't output the last entry to the object: it outputs what is stored from before, then stores and shifts in the new value and doesn't output this until the next value is received.
Will this not make the average and the derivatives unprecise? The former when it comes to averages over few numbers or small datasets (as it will lose one factor) and the latter, as the first derivative will be of the penultimate and third last value (and the second derivative will be of the third and the fourth last value) from the drunk object?
@roman: Which was kind of what I was aiming to clarify in the sentence following up my question. "It doesn't matter due to data input being fast and dense" doesn't mean that one shouldn't be aware of the timeshift when using this technique of handling data, specifically if you are using the treated data in direct relation to the input. I felt this was missing from the tutorial and thus worth a question, as I didn't have a laptop with Max in front of me at the time. As Rick replied: There is the flag to counteract this.
I see everyone discussing the bucket object for calculating running averages and got curious: is there some advantage I'm missing in calculating it using bucket instead of my approach (zl.stream)? Or is it just out of curiosity? Anyway, I revised the patch I posted above. Since I can dynamically change the "smoothing factor" (number of samples to average), I've noticed a problem: when you change it, the buffer needs to be refilled, which causes a temporary pause in the output. This can be avoided with the inclusion of another zl.stream. This way you would be able to smoothly tweak the smoothing factor, an essential requirement in a live performance context.
Just two quick notes: - the patch is aimed at sensors with continuous output. In other types of non-continuous streams of data, I would just continuously sample them. - there's an initial delay before this approach starts its output, related to the buffer being filled, but that does not mean that the output values are delayed by the buffer size value.
the bucket (or funnel or unpack or trigger or zl nth) solutions are just more oldschool and people still have these as their custom abstractions installed.